

RAG (Retrieval-Augmented Generation): O Futuro da Inteligência Artificial Conversacional
Nos últimos anos, a Inteligência Artificial (IA) tem alcançado avanços extraordinários, especialmente no campo de modelos de linguagem. Uma abordagem emergente que tem ganhado destaque é o RAG (Retrieval-Augmented Generation). Essa metodologia combina o melhor dos modelos generativos com a recuperação de informações para criar respostas mais precisas, contextuais e baseadas em fatos.
Neste artigo, exploraremos o que é RAG, como ele funciona e por que é um marco significativo na evolução da IA conversacional.
O que é RAG?
O RAG é uma arquitetura de modelo de IA que combina dois elementos principais:
- Recuperação de Informações (Retrieval): Utiliza bancos de dados ou conjuntos de documentos para buscar informações relevantes relacionadas à pergunta ou ao contexto fornecido pelo usuário.
- Geração de Respostas (Generation): Usa um modelo generativo, como o GPT, para construir uma resposta usando as informações recuperadas como base.
Essa combinação permite que o RAG resolva uma das principais limitações dos modelos de linguagem pura: a tendência de “alucinações” ou respostas imprecisas, especialmente quando confrontados com questões específicas ou complexas.
Como o RAG Funciona?
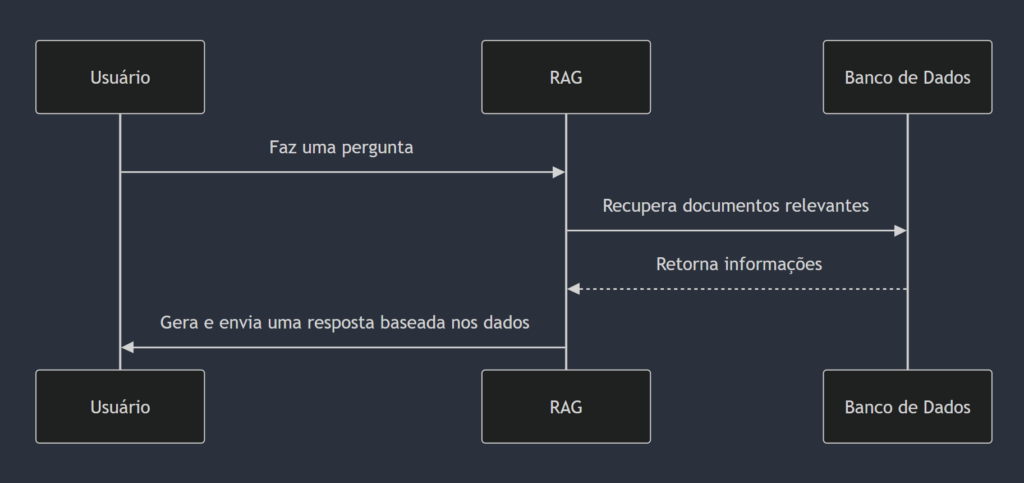
A arquitetura do RAG pode ser dividida em três etapas principais:
- Entrada do Usuário: Uma pergunta ou comando é fornecido.
- Fase de Recuperação:
- Um componente de busca, como o Dense Retriever (baseado em embeddings vetoriais), acessa uma base de dados ou documentos.
- Os documentos mais relevantes são selecionados.
- Fase de Geração:
- O modelo generativo utiliza os documentos recuperados como contexto para produzir uma resposta.
- A resposta é geralmente mais precisa e informada, pois está ancorada nos dados recuperados.
Fluxo de Trabalho Simplificado:
Por que o RAG é Importante?
1. Precisão e Contexto
Modelos generativos tradicionais, como o GPT, têm limitações ao lidar com perguntas específicas que exigem conhecimento factual atualizado. O RAG resolve isso ancorando as respostas em dados reais recuperados.
2. Escalabilidade
O RAG pode ser usado com grandes repositórios de dados, como artigos científicos, documentações técnicas e bases de conhecimento corporativas, permitindo aplicações em larga escala.
3. Flexibilidade
Ele é aplicável em diversos cenários:
- Atendimento ao cliente: Fornecendo respostas precisas para dúvidas de usuários com base em FAQs e documentos internos.
- Pesquisa e Educação: Assistindo em estudos acadêmicos ao recuperar informações relevantes de artigos científicos.
- Saúde: Auxiliando profissionais ao acessar bases de dados médicas atualizadas.
Desafios do RAG
Embora o RAG seja incrivelmente poderoso, ele também enfrenta desafios:
- Qualidade dos Dados: A precisão das respostas depende da relevância e qualidade dos documentos armazenados.
- Complexidade Computacional: A combinação de busca e geração pode ser intensiva em recursos.
- Atualização de Dados: Manter a base de dados atualizada é fundamental para evitar respostas desatualizadas.
Como Começar com o RAG?
- Escolha sua Base de Dados: Selecione um repositório de dados relevante ao seu caso de uso. Pode ser um banco de dados SQL, Elasticsearch ou arquivos locais.
- Use um Retriever Eficiente: Ferramentas como FAISS, Elastic ou retrievers baseados em embeddings são ideais.
- Integre um Modelo Generativo: Modelos como o GPT-4 podem ser usados para a geração.
- Combine as Peças: Implemente a arquitetura de comunicação entre o retriever e o modelo generativo.
Ferramentas Recomendadas:
- Hugging Face Transformers: Para modelos de linguagem e embeddings.
- LangChain: Uma biblioteca para facilitar a criação de pipelines RAG.
- FAISS: Para buscas vetoriais eficientes.
O RAG representa um grande passo para o futuro da IA conversacional e de assistentes virtuais, combinando a criatividade dos modelos generativos com a precisão da recuperação de dados.
Seu potencial de aplicação é vasto, e à medida que mais desenvolvedores começam a adotar essa tecnologia, podemos esperar soluções ainda mais inovadoras.
Se você é desenvolvedor ou entusiasta de IA, começar a explorar o RAG pode ser uma excelente forma de se destacar nesse campo em constante evolução.
Referências
- Documentação Oficial do LangChain
- Guia completo sobre a criação de pipelines que integram busca e geração de texto usando RAG.
- Blog da Hugging Face
- Artigos e tutoriais sobre modelos de linguagem e aplicações de IA.
- FAISS: Biblioteca de Busca Vetorial
- Repositório oficial para implementação de buscas eficientes baseadas em embeddings.
- Introdução ao RAG no Hugging Face
- Post detalhado explicando como implementar RAG utilizando ferramentas da Hugging Face.
- Pesquisa de IA no Google AI Blog
- Novidades e avanços em IA, incluindo aplicações de recuperação e geração de texto.
Tem interesse em um tutorial prático sobre como implementar o RAG? Deixe seu comentário!
Os comentários estão fechados, mas trackbacks E pingbacks estão abertos.